
[Paper Review] Generating Summaries with Controllable Readability Levels (EMNLP 2023)
Published:
가독성을 조절하여 요약문 생성하기
Abstract
글의 가독성에 미치는 요소들은 다양하다. 글이 얼마나 복잡하게 쓰였는지, 글의 주제, 독자의 배경 지식 등 가독성에 영향을 주는 요소들은 많다. 따라서, 요약문을 생성할 때, 독자들마다 다른 가독성의 글을 만드는 것이 필요하다. 하지만 현재는 독자의 전문성에 따른 조절이 불가하기에 해당 논문에서는 정밀한 조절을 하는 방법에 대해 제안한다. 총 3가지 모델, 1) instruction-based, 2) reinforcement learning 3) lookahead decoding 접근 방법을 제안한다.
Introduction

글의 가독성은 독자의 이해도에 큰 역할을 한다. 높은 가독성의 글은 읽는 노력을 줄이고 읽는 속도를 빠르게 하며, 이해력이 부족한 독자들이 더 편하게 읽도록 도움을 준다. 반면 낮은 가독성은 자세하고 명확하다. 따라서 요약문의 가독성은 더 많은 독자들의 다양한 지식과 이해도를 수용해야해서 중요하다. 기존의 연구들은 전문가 혹은 비전문가의 binary한 조절에 집중했다. 하지만 해당 논문에서는 더 fine-grained한 조절 방법에 대해 제안한다. 위의 그림에서 보이는 것처럼 가독성 레벨이 높은 글의 경우 쉬운 단어, 짧은 문장, 낮은 전문성을 띄는 형태를 보이지만, 가독성 레벨이 낮은 글의 경우, 복잡한 문장 구조, 어려운 단어, 자세한 설명 등이 포함된다.
해당 논문에서는 이러한 글의 가독성을 조절하기 위해서 3 가지 방법을 제안한다. Instruction-prompting은 특정 가독성 점수나 카테고리를 프롬프트에 적어주는 방식을 사용하고, reinforcement learning은 PPO와 Gaussian-based reward를 통해 너무 큰 편차는 페널티를 주는 방식을 사용한다. 마지막으로 가독성 기반 lookahead decoding 방법은 각 디코딩 스텝마다 예상 미래 토큰의 가독성을 기반하여 토큰을 선택한다.
Task Definition: Summaries with Distinct Readability Levels
Task Statement
요약문은 본문의 중요한 내용을 포함시키는데, 동시에 가독성을 고려하는 것은 어려운 문제이다. 해당 방법에서는 요약문의 정보성과 독자의 배경 지식에 따른 가독성의 밸런스를 맞추어야 한다.
Readability Metrics
보통 가독성은 글의 문법 구조, 문장 구조, 일관성, 독자의 이해도에 영향을 받는다. 따라서 가독성을 측정하는 평가할 때에는 구절의 복잡성과 품질, 단어의 난이도, 구조 등을 평가한다. 해당 논문에서는 Flesch Reading Ease (FRE), Gunning fog index (GFI), Coleman-Liau index (CLI)를 통해 평가하며 FRE는 높을수록, GPI, CLI는 낮을수록 좋다.
Controllable Methods for Readabilty
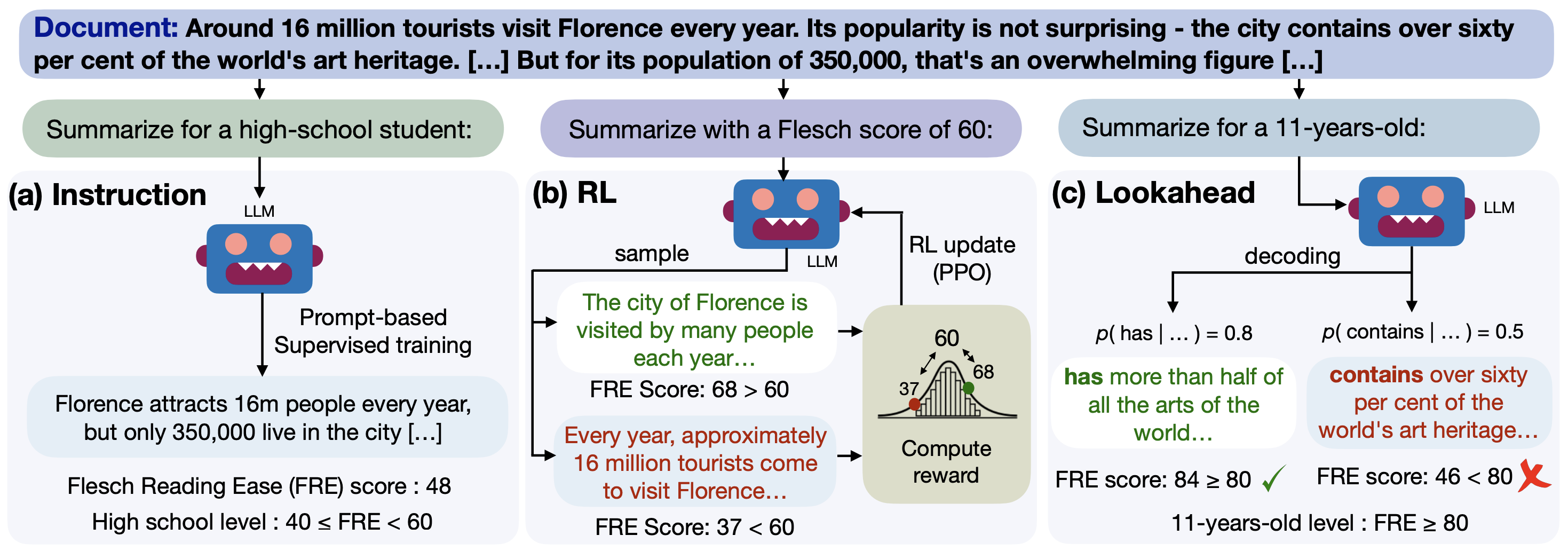
Instruction-Aligning Readability Methods
Instruction-tuning을 할 때에는 본문 앞에 프롬프트를 붙여서 학습한다. Category-based Instructions을 사용할 때에는 정답 요약문을 특정 FRE 점수에 따라 카테고리를 분류한 후 해당 카테고리를 instruction에 제공한다. Inference 단계에서는 출력하고 싶은 카테고리를 넣어서 사용하면 된다. 해당 방법을 CATEGORYINSTRUCT라 한다.
Score-based Instructions를 사용할 때에는 카테고리가 아닌 실제 점수를 instruction에 제공한다. 해당 방식을 사용하면 category-based보다 더 정밀한 조절이 가능하며 해당 모델은 SCOREINSTRUCT라 한다.
Reinforcement Learning for Readability Control
Instruction-tuning 후에 reinforcement learning을 사용하면 좋은 효과를 보인다는 기존의 연구들이 있었다. 따라서, 해당 모델에서도 동일하게 사용하며, reward로는 가독성 평가 점수에 따라 제공한다.
Reward는 최대 1.0으로 설정하며, 원하는 가독성 수치를 중심 값으로한 normalized Gaussian 분포에서의 생성된 요약문의 가독성 수치 값을 reward로 사용한다. 수치가 비슷하면 리워드 감소를 조금하고, 수치의 차이가 크다면 리워 감소를 많이 한다. 자세한 식은 아래와 같다.
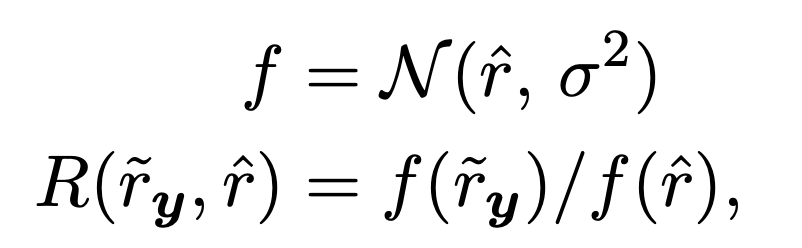
해당 모델에서 reinforcement learning 방법으로 PPO를 사용한다. 요약 모델이 supervised-tuning을 통해 가지고 있는 salience와 coherence를 유지하기 위해 RL policy로 SCOREINSTRUCT 모델을 사용한다. PPO가 적용된 모델을 SCOREINSTRUCT+RL이라 한다.
Lookahead Readability Decoding
RL을 통해 가독성 reward를 최대화하더라도, RL은 높은 품질의 supervised 모델로 초기화가 필요하다. 이런 세팅이 언제나 가능한 것은 아니기에, 해당 논문에서는 inference단계에서 적응이 가능한 decoding 방법인 lookahead를 사용한다. Lookahead 방법을 통해서 가독성이 높은 토큰을 생성하도록 likelihood를 조절한다. 수식은 아래와 같으며, $w$를 통해서 생성 과정에서 가독성을 조절한다.
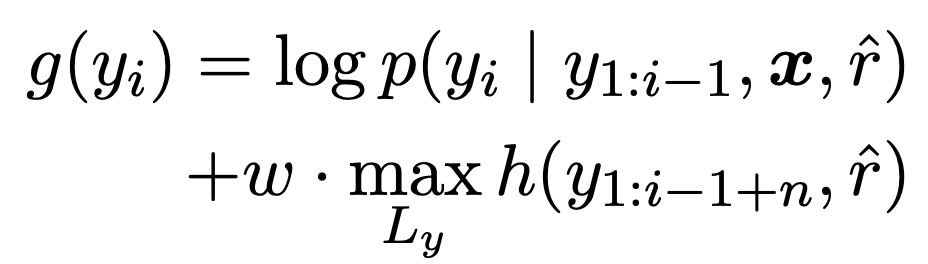
Results and Analysis
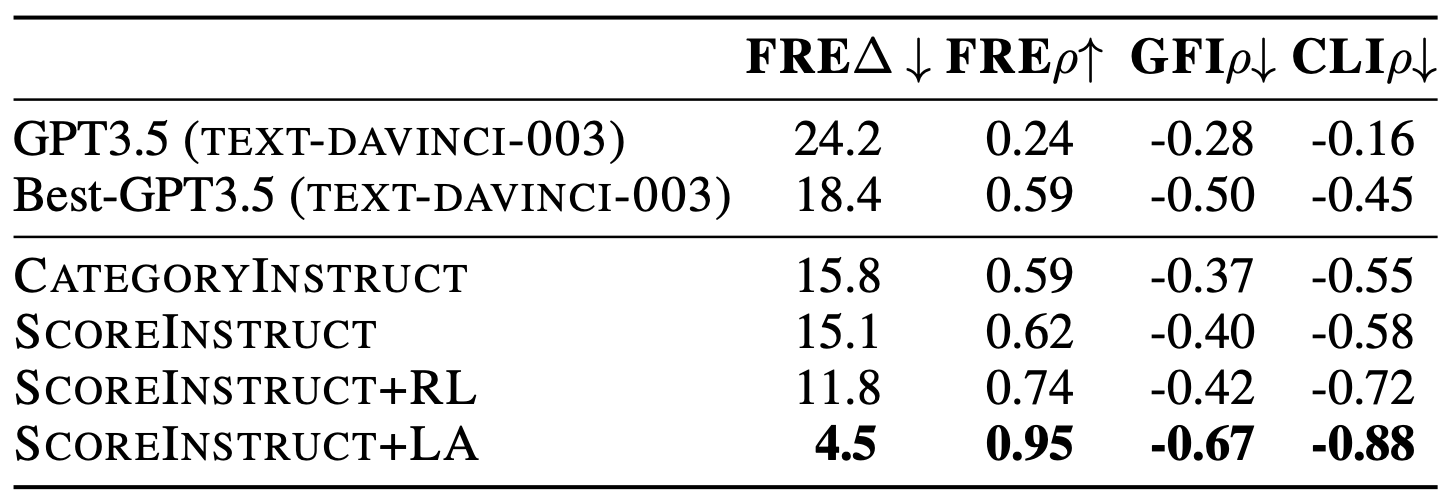
위의 테이블을 보면, 각 방법들이 성능 향상을 가져오는 것을 볼 수 있다. 특히 모든 모델들이 GPT3.5보다 좋은 성능을 보이며, lookahead를 적용한 모델은 큰 점수 차이로 좋은 성능을 보이는 것을 볼 수 있다.
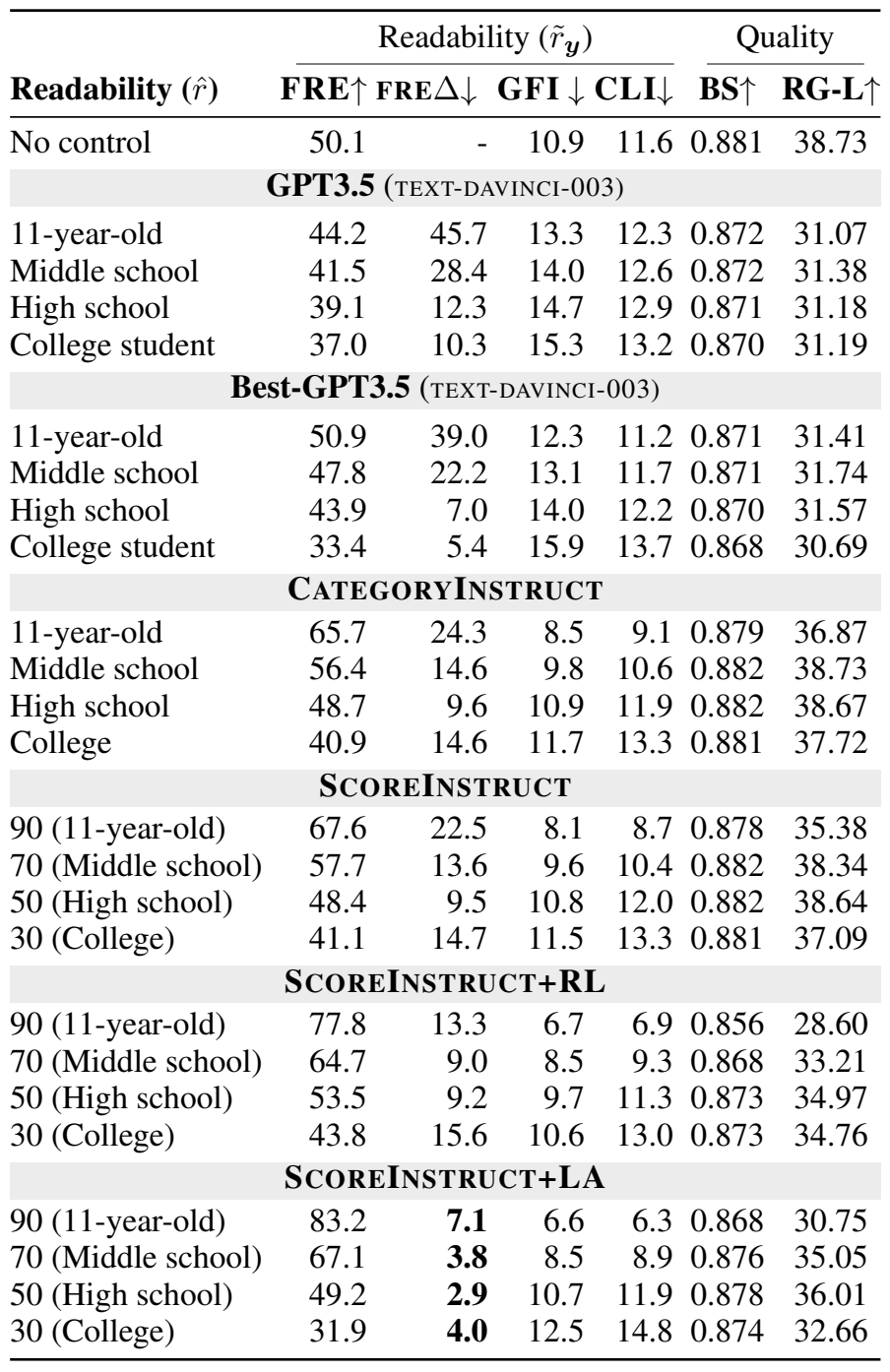
위의 테이블에서 가독성 조절을 통해 생성한 요약문의 평가를 볼 수 있다. 가독성을 90점(11살 수준)으로 조절한 요약문의 경우 대부분의 모델들이 높은 가독성 평가 점수를 보이고, 가독성 점수가 내려갈수록, 가독성 평가 점수가 내려가는 것을 볼 수 있다.
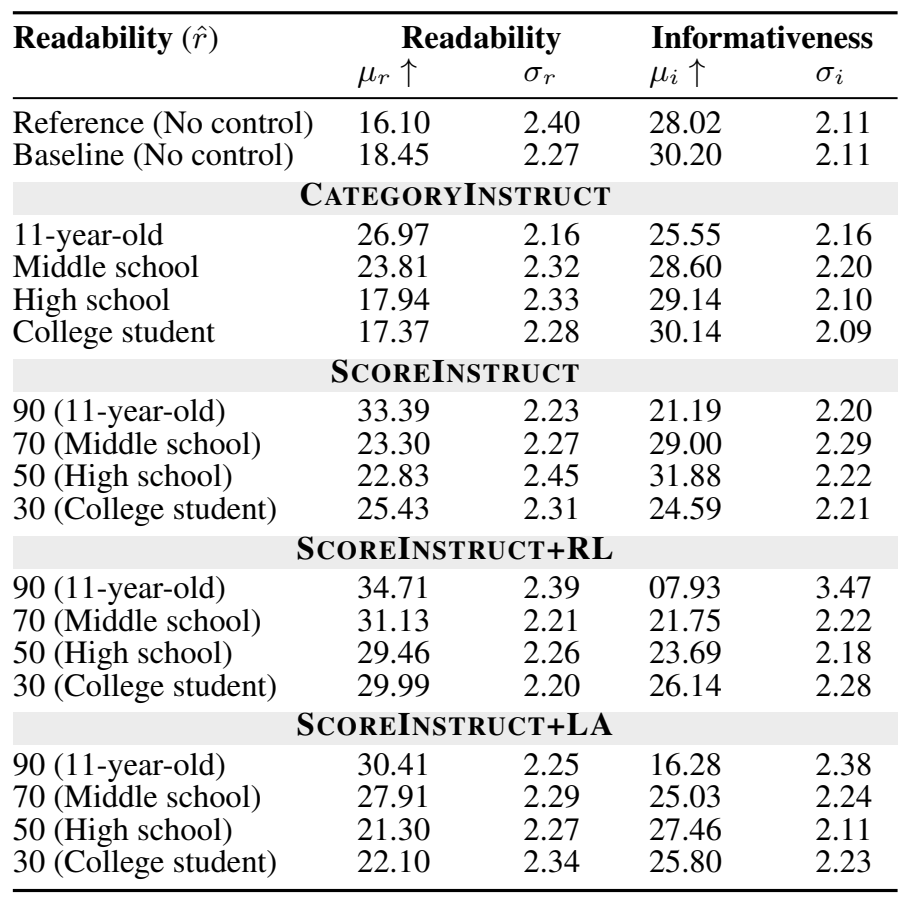
위의 테이블은 Amazon Mechanical Turk (AMT) human evaluation 결과이다. 해당 수치를 보면 lookahead를 사용한 방법의 informativeness가 생각보다 높지 않은 것이 눈에 띈다. 반면 CATEGORYINSTRUCT와 SCOREINSTRUCT 방법에서 readability가 조절한 가독성 점수 별로 차이가 있는 것과 informativeness가 높은 것이 눈에 띈다.
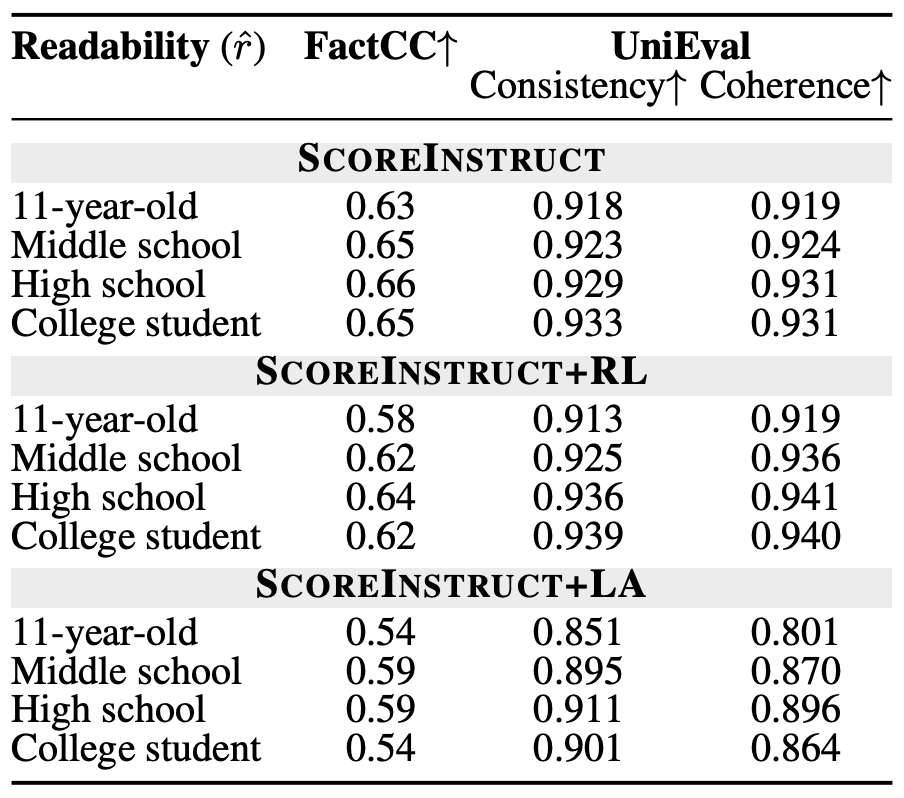
위의 테이블에서는 factuality, consistency와 coherence 결과를 보여준다. 해당 지표들은 요약 태스크에서 굉장히 중요하다. 반면, 가독성을 조절하면서 해당 지표들을 유지하는 것은 어려운 문제다. 테이블을 보면, 쉽게 쓰여진 요약문의 경우 사실성이 비교적 낮은 것을 볼 수 있다. 해당 테이블에서는 SCOREINSTRUCT+RL 모델이 가장 높은 UniEval 점수를 보였다.
Comment
해당 논문에서는 instruct-tuning, reinforcement learning, lookahead decoding 3 가지 방법을 통해서 요약문의 가독성을 조절했다. Instruct-tuning에서 요약문의 가독성을 프롬프트에 입력해서 학습하는 것이 인상적이었고, reinforcement learning에서는 가우시안 분포를 기반으로 reward를 주는 것이 새로웠다. Lookahead decoding 방법에 대해서 자세히 설명하지 않아서 아쉬웠지만, 학습 없이 decoding 과정에서 likelihood만을 조절해서 요약문의 품질을 조절하는 것이 흥미로운 발상이었다. 해당 논문에서는 다양한 방법과 많은 실험을 했지만, 여러 실험들에서 자신의 모델에서 유리한 지표만 작성이 된 것 같은 느낌이 들었다.